< Gérer les 'Page Fault' | TutoOS | Implémenter les signaux >
Un premier shell
- Un processus qui utilise la console
- Créer un nouveau processus
- Allouer dynamiquement de la mémoire ŕ un processus avec malloc()
- Le noyau et un premier shell
Les sources
Le package contenant les sources est téléchargeable ici : kernel_Shell.tgz
Pour naviguer dans l'arborescence : Shell
Un processus qui utilise la console
Nous avons vu dans un chapitre précédent comment gérer les interruptions du clavier pour saisir des caractčres et afficher un message directement sur la console. La réalisation d'un shell demande d'aller un peu plus loin dans le traitement de ces interruptions pour que les caractčres saisis soient effectivement "lus" par le shell. Cette partie montre une implémentation simple permettant ŕ de multiples processus d'utiliser une console pour saisir et afficher des caractčres.
Attacher une console ŕ un processus pour gérer les entrées/sorties d'un terminal
Au démarrage, le noyau initialise une console par défaut grâce ŕ la structure struct terminal.
Cette structure contient deux champs, pread et pwrite, qui pointent vers les processus qui utilisent la console en lecture ou en écriture. Dans cette architecture, un seul processus peut donc lire ou écrire ŕ la fois.
Le pointeur current_term indique quel est le terminal actuellement en cours d'utilisation.
L'implémentation actuelle n'utilise qu'un seul terminal, mais ce pointeur devient indispensable dans l'hypothčse oů plusieurs terminaux existent.
Ŕ sa création, un processus est rattaché ŕ la console en court par le biais du champ term :

Utiliser l'appel systčme sys_console_read() pour entrer des données au clavier
Quand un processus souhaite lire des données entrées au clavier, il invoque l'appel systčme sys_console_read() en passant en paramčtre l'adresse d'un buffer d'entrée (inbuf dans le schéma ci-dessous). Si un autre processus utilise déjŕ la console en lecture, le processus se met en attente jusqu'ŕ ce qu'elle se libčre. Ensuite, l'appel systčme sys_console_read() fait pointer le champ pread de la structure du terminal sur le processus en attente de caractčres ŕ lire :
while (current_term->pread);
current->console->term->pread = current;
current->console->inlock = 1;
/* Bloque jusqu'a ce que le buffer utilisateur soit rempli */
while (current->console->inlock == 1);

Quand une touche est pressée, une IRQ est levée et la fonction isr_kbd_int() est activée. Cette fonction lit le code émis par le clavier. Si le code correspond ŕ la saisie d'un caractčre, la fonction putc_console() est appelée.
En mode buffer (le mode le plus général), putc_console() affiche le caractčre ŕ l'écran et l'ajoute dans le buffer de la console, console->inb, du processus en lecture :

Une fois que le caractčre \n est saisi, le processus est détaché de la console et pread prend la valeur NULL. C'est seulement dans un deuxičme temps que le contenu du buffer inb est copié dans le buffer d'entrée de l'espace utilisateur du processus :
while (current->console->inlock == 1);
strcpy(u_buf, current->console->inb);
return strlen(u_buf);
Pourquoi ne copions nous pas directement le caractčre dans le buffer inbuf du processus en attente de lecture ?
Quand un caractčre est saisi, une interruption est levée et interrompt le processus en cours qui n'est pas forcément le processus en lecture.
Pour copier le caractčre dans le tampon inbuf du processus en lecture, il faudrait alors changer d'espace d'adressage, copier le caractčre, puis revenir dans l'espace d'adressage du processus courant. J'ai préféré l'autre solution qui est de copier le caractčre dans un buffer intermédiaire situé directement dans la structure struct console, donc dans l'espace du noyau :
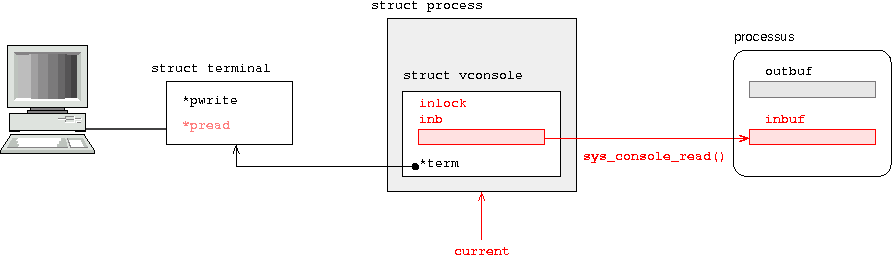
Le code de l'appel systčme sys_console_read() : syscalls/sys_console_read.c
#include "lib.h"
#include "process.h"
#include "console.h"
int sys_console_read(char *u_buf)
{
if (!current->console->term) {
printk("DEBUG: sys_console_read(): process without term\n");
return -1;
}
/* Bloque si la console est deja utilisee */
while (current_term->pread);
current->console->term->pread = current;
current->console->inlock = 1;
/* Bloque jusqu'a ce que le buffer utilisateur soit rempli */
while (current->console->inlock == 1);
strcpy(u_buf, current->console->inb);
return strlen(u_buf);
}
Le code de la fonction putc_console() : console.c
#include "console.h"
#include "process.h"
/*
* Pour copier un caractere dans le buffer utilisateur, il faut etre dans le
* contexte du processus en question !
*/
void putc_console(char c)
{
struct process *p;
/* En l'absence de console, on ecrit directement dans la memoire video */
if (!current_term || !(p = current_term->pread) || p->state<1) {
putcar(c);
return;
}
if (p->console->mode == 0) { /* Not buffered mode */
putcar(c);
p->console->inb[0] = c;
p->console->term->pread = 0;
p->console->inlock = 0;
} else { /* Buffered modes */
if (c == 8) { /* backspace */
if (p->console->keypos) {
p->console->inb[p->console->keypos--] = 0;
if (p->console->mode == 1)
putcar(c);
}
}
else if (c == 10) { /* newline */
if (p->console->mode == 1)
putcar(c);
p->console->inb[p->console->keypos++] = c;
p->console->inb[p->console->keypos] = 0;
p->console->term->pread = 0;
p->console->inlock = 0;
p->console->keypos = 0;
}
else {
if (p->console->mode == 1)
putcar(c);
p->console->inb[p->console->keypos++] = c;
}
}
}
Créer un nouveau processus
L'appel systčme sys_exec() (syscalls/sys_exec.c) permet de créer et d'exécuter un nouveau processus.
C'est un appel systčme trčs simple qui :
- vérifie que le nom du fichier exécutable passé en argument correspond bien ŕ un fichier
- appelle la fonction
load_task()
#include "list.h"
#include "io.h"
#include "lib.h"
#include "file.h"
#include "process.h"
int sys_exec(char *path, char **argv)
{
char **ap;
int argc, pid;
struct file *fp;
if (!(fp = path_to_file(path))) {
printk("DEBUG: sys_exec(): %s: command not found\n", path);
return -1;
}
if (!fp->inode)
fp->inode = ext2_read_inode(fp->disk, fp->inum);
ap = argv;
argc = 0;
while (*ap++)
argc++;
cli;
pid = load_task(fp->disk, fp->inode, argc, argv);
sti;
return pid;
}
Passer des arguments ŕ un programme
La fonction load_task() a été modifiée pour permettre le passage d'arguments du processus parent au processus enfant.
La fonction principale main() prend ses arguments sur la pile (comme d'ailleurs toute fonction). Y placer ces arguments pour les rendre disponibles au nouveau processus ne pose pas de difficulté particuličre. Mais oů copier les chaînes de caractčres ŕ passer en paramčtre ?
Une solution est de les copier ŕ un extrčme de l'espace d'adressage afin de ne pas géner le développement de la pile ou du heap. Deux emplacements semblent alors possibles : soit avant le heap utilisateur, soit au sommet de la pile. Cette derničre solution, standard sous Unix, est celle que nous avons implémenté :

Le code qui copie les données d'espace utilisateur ŕ espace utilisateur (ici du processus parent au processus enfant) comporte une subtilité ! Ŕ un moment donné, on ne peut accéder qu'ŕ un seul espace. Il faut donc faire transiter ces données par l'espace du noyau, qui est commun. La copie se fait donc en deux temps. La création du nouveau processus se fait ensuite comme ŕ l'accoutumé.
Allouer dynamiquement de la mémoire ŕ un processus avec malloc()
L'implémentation de malloc() repose sur l'appel systčme sys_sbrk() : syscalls/sys_sbrk.c
char* sys_sbrk(int size)
{
char *ret;
ret = current->e_heap;
current->e_heap += size;
return ret;
}
Cet appel systčme trčs simple ne fait que mettre ŕ jour le pointeur qui pointe sur le sommet du heap. Mais oů commence le heap ? La fonction load_elf(), qui charge l'exécutable, a été modifiée pour mettre ŕ jour les pointeurs sur le début et la fin des zones de code et de données. A partir de ces valeur, la fonction load_task() peut évaluer la base du heap. L'utilisation de la mémoire virtuelle par le processus correspond alors au schéma suivant :

L'implémentation des fonctions malloc() et free() repose sur les męmes principes que pour les fonctions kmalloc() et kfree() du noyau. Attention au fait qu'il s'agit lŕ d'une implémentation trčs simple pour gérer des blocs de mémoires au niveau de l'espace utilisateur !
Le noyau et un premier shell
Les sources du shell sont dans Shell/userland. Le répertoire contient également les sources d'une mini-bibliothčque de fonctions et les sources de la commande cat qui permet d'afficher le contenu d'un fichier.

< Gérer les 'Page Fault' | TutoOS | Implémenter les signaux >